Note
This technote is not yet published.
Use cases, scope definition, and proposed implementation for a campaign management system.
1 Definitions¶
A production is a large-scale class of processing, including the iterations of the Data Release Production and the Alert Production. A campaign is a data processing activity that accomplishes a particular goal. It achieves this by executing one or more workflows, which are submissions to a workflow management tool with specific, defined configurations processing specific, defined datasets. Those workflow submissions result in the execution of jobs, each of which is a sequence of Tasks that runs on a single worker machine. In the Gen3 Middleware, a job is typically a pipeline of PipelineTasks defined by YAML. A Task is an instance of the Python pipe_base.Task class, configured by a pex_config.Config instance.
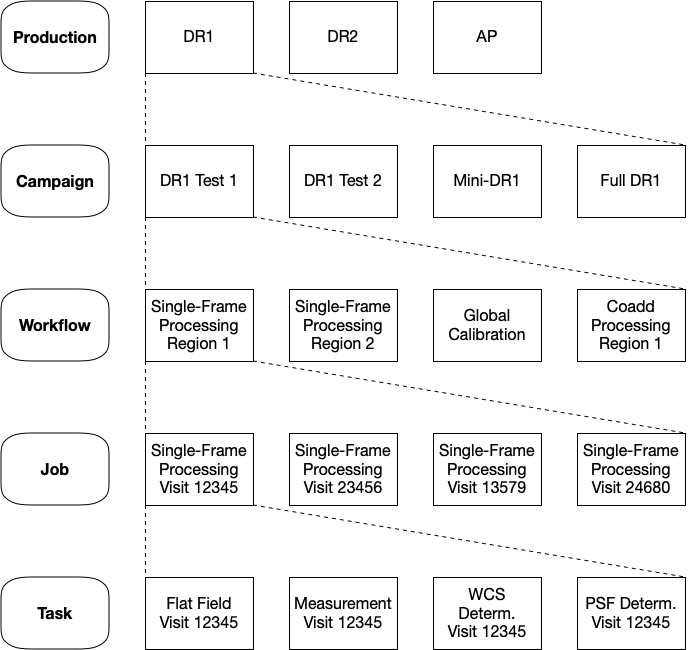
Figure 1 Campaign managment definitions.
Campaign Management is a tool that assists in the definition, execution, monitoring, and analysis of campaigns.
2 The Vision¶
To help illustrate the proposed role and scope of a Campaign Management system, several use cases are outlined.
2.1 Data Release¶
The Data Release Board determines the configurations and datasets to be processed for a release, specifying that certain input images are to be excluded. The exclusion list was determined by querying the Engineering and Facilities Database, querying the metrics resulting from Alert Production processing, and follow-up investigation of issues noticed by human operators. It is specified as a list of DataIds in JSON format. The configuration information includes a Science Pipelines tag (which in turn implies exact conda package builds in the environment), pex_config override files, YAML pipeline definitions, and overall workflow definitions. This culminates in a series of Batch Production Service (BPS) commands, each representing a workflow submission, that are to be executed, possibly with human analysis in between. Each workflow in turn results in multiple jobs being executed on the batch systems. Note that the Data Release Production is not expected to be run as a single workflow submission for a variety of reasons:
- Quantum Graph generation currently takes a long time, particularly as the graph gets more complex; smaller graphs should be non-linearly faster to generate
- resource limitations such as available scratch space that may be easier for humans to manage than the workflow system
- global synchronization points that form natural places to break up the overall workflow
- user intervention points where analysis of what has been completed and potentially patching of code or configuration may be desirable before continuing
- allowing simpler restart after failure
The exclusion list and configuration information is checked into a git repository and tagged. The Data Release Lead Campaign Manager, a role in the Execution team, is told to execute the campaign defined by this input data and processing specification.
The DRLCM begins by defining the campaign in the Campaign Management system. A campaign identifier is automatically generated, but the DRLCM provides information such as a short name, a long description including the reason why this campaign is being run, and links to the data and processing specifications.
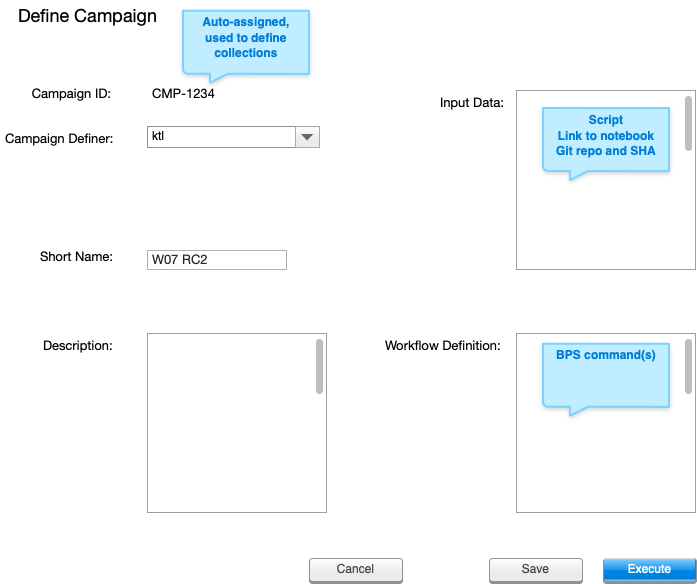
Figure 2 Sketch of a campaign definition screen.
After defining the campaign, the DRLCM can save it or begin execution by running the first BPS command to submit the first workflow. (Initially, command execution will be manual, but eventually it may be integrated into the Campaign Management system.)
As the campaign executes, each workflow submission can be assigned one or more Operators to ensure that it is running properly. Operators may take shifts, defined by a schedule. (Initially, Operator assignments and changes of assignment will be manually entered into the Campaign Management system, but eventually the system may allow a schedule to be defined and automatically applied.)
The progress of each workflow submission is monitored through the workflow system. Results of each workflow submission are placed in a Butler Repository (for data products), a metric system (like SQuaSH), or a quality assurance analysis system (for things like plots). The Campaign Management system provides links to each of those external systems for easy access.
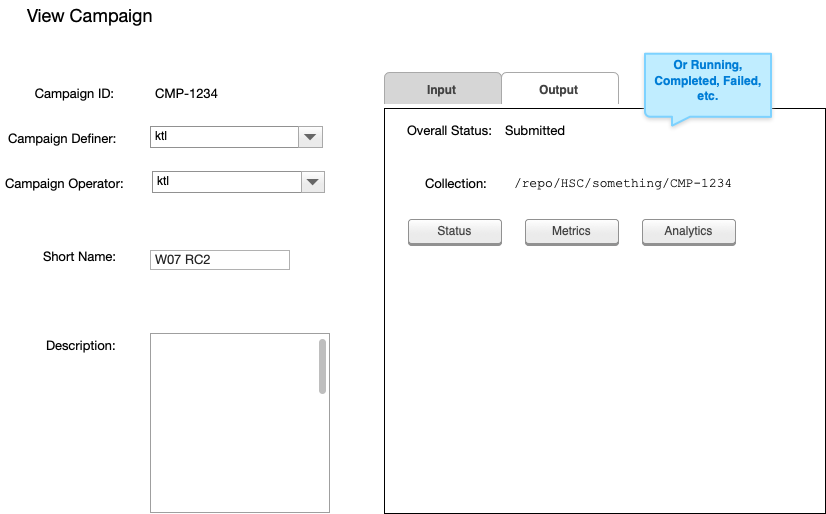
Figure 3 Sketch of a campaign viewing screen.
A list of all the campaigns can be generated, with sorting and filtering by campaign attributes. (Eventually saved queries and the ability to rerun previous campaigns with modifications may be provided.)

Figure 4 Sketch of a campaign list screen.
As each workflow submission completes, the campaign is marked as “Paused” in the Campaign Management system while a determination is made to continue. (Initially, this marking will be manual, but eventually it may be integrated into the system.) When the entire campaign is complete, it is marked as “Completed” or “Failed” appropriately.
2.2 Mini-Data Releases¶
The final configuration for a Data Release will be arrived at via an iterative process. Small “development” runs will test out new Science Pipelines features. Larger “integration” runs will ensure that unusual data does not cause problems. Finally, a “mini-DRP” run, on the scale of 8% of the sky, will be executed to prove the data selection, configuration, and (human) processes. The Science Pipelines, System Performance, and Execution teams will meet throughout this process, under the leadership of the DRLCM.
The Campaign Management system will be used for each of these smaller runs, allowing progress (and setbacks) to be monitored, reproduced, and tracked.
2.3 Alert Production¶
Each night’s Alert processing and daytime Solar System processing can be considered a campaign. It would similarly have a definition of the software and configurations to be used, and exclusion lists might be generated by the Observatory Operator (e.g. if it is known before processing begins that a certain image will be bad). Each visit causes an effective workflow submission, although the Alert Production execution framework may not use the Batch Production Service and workflow management at all.
2.4 Commissioning¶
In Commissioning, both applying the same processing to different data and applying different processing to the same data will occur frequently. Being able to view the definitions of past campaigns and adjust the input datasets or pipeline configurations assists with this.
3 The Scope¶
The Campaign Management system sketched in the above use cases serves as a sort of electronic lab notebook, recording parameters and providing links to other systems that do the actual work of executing workflows or rendering plots. It is a system to manage campaigns, not one to execute them, although rudimentary execution capabilities (submit the next BPS command in sequence) can be added in later versions. Its primary interfaces are human-oriented, not machine-oriented. It is usable by staff, including developers, Commissioning staff, and Execution team members. It is not initially usable by science users, although with appropriate multi-user security and controls, it could be extended to them.
The generation of inclusion/exclusion lists is acknowledged to require extreme flexibility, with information coming from any available source, including a random number generator. As a result, only a format for specifying the exclusion list is defined; the mechanisms and tools for generating such a list are left outside the scope of Campaign Management. In particular, the Exposure Log (LSE-490 [3] §3.2.4.2 and DMTN-173 [2]) cannot be sufficient to generate inclusion/exclusion lists; it is but one source of information that goes into their generation. Inclusion/exclusion lists must be uploaded to the Butler Registry in order to enable joins with other tables and in order to maintain provenance.
4 The Proposed Implementation¶
The Middleware Team will write a tool to upload sets of DataIds in a file in JSON format to a Butler Registry. This will require creating a new table in the Registry schema to hold this new “DataId Set” concept; the resulting sets will be persistent and sharable. The DataIds must use primary dimension keys in their JSON representation; these can be obtained from the Registry or astro_metadata_translator. The Middleware Team may create a batch API to aid in performing this conversion to primary keys, but otherwise it is the user’s responsibility.
DataId sets may initially be temporary, but eventually they will have to be persistent as they are used in provenance. They will be visible to everyone using the same Registry in initial “friendly user” mode. For science users, however sharing permissions, derived collections, and quota issues will need to be worked out.
Note that a DataId list can be turned into a Collection if it is combined with one or more Dataset Types.
At a later time, the Middleware Team may support an additional, more human-friendly upload file format, perhaps based on CSV.
The Middleware Team will create an API to enable such a “DataId Set” to be resolved into a set of datasets that can be persisted as a user-defined TAGGED Collection.
The Middleware Team will modify the pipetask command-line execution tool to allow the upload of sets of DataIDs in upload file format into temporary tables that can be used in the data query expression as inclusion or exclusion conditions.
It is expected that users will develop their own tools/scripts/notebooks for querying all relevant available data sources, including the EFD, the Exposure Log, the Registry, SQuaSH and other QA metrics, and external references, in order to generate DataId sets in upload file format. The Middleware Team may develop libraries or frameworks to simplify writing these, particularly emphasizing VO query integration.
The current process for executing production-like integration-level campaigns uses Jira to convey information from the campaign definer(s) to the execution team. DMTN-167 [1] contemplates using Jira ticket identifiers as collection names. The creation/editing/viewing capabilities of Jira seem well-aligned with the anticipated needs. Jira has REST APIs available for automating the creation of campaigns, as would likely be needed if it were to be used for Alert Production. Accordingly, a customization of Jira is proposed to be investigated first as a potential implementation technology for the Campaign Management system.
References
| [1] | [DMTN-167]. Jim Bosch. Policies and Conventions for Organizing Gen3 Data Repositories. 2021. LSST Data Management Technical Note. URL: https://dmtn-167.lsst.io |
| [2] | [DMTN-173]. Frossie Economou. The Observatory Logging Ecosystem. 2020. LSST Data Management Technical Note. URL: https://dmtn-173.lsst.io |
| [3] | [LSE-490]. Sandrine Thomas, Chuck Claver, Kevin Reil, Brian Stalder, Tim Jenness, and Doug Williams. Observatory Electronics Logging Working Group Report. 2020. LSST Data Management Technical Note. URL: https://docushare.lsst.org/docushare/dsweb/Get/LSE-490 |